
Detections as Code in DataDog: How I Built an MVP for a Small Team
Cybersec Café #82 - 09/02/25


Over the past couple weeks, I’ve been heads-down building out a Detections as Code (DaC) implementation for my Security Operations team.
In past roles, I've worked with DaC setups, but they were always there before my arrival - already somewhat mature with the needed infrastructure in place.
But this time is different. I’m maturing the SecOps function from scratch. That means I have full creative control over how this solution gets built (within the constraints of the platform, of course).
It’s a project that’s been pushed down the backlog a few times for more urgent fires, but I finally carved out time to sit down in my IDE and get started.
Our SIEM of choice in this instance is DataDog. While they provide some high-level resources on DaC setup, primarily in the form of a blog article, they leave much of the implementation open-ended.
That freedom has given me the space to design something that works not only for us today, but hopefully scales well and sticks around long after I’ve moved on.

Why Detections as Code?
We’re a small team, which means bandwidth is always stretched. That’s the main reason DaC has been on the backburner for months.
At first, our priority was coverage. We needed detections in place, fast - with the understanding that we’d later port them into an “as Code” framework.
But here’s the challenge: with just two senior engineers, one mid-level, and two analysts, time is our most precious resource. And DaC has some heavy up front cost: setting up pipelines, porting detections, and ironing out bugs.
But most of that cost is front-loaded. Once the pipelines and infrastructure are running, maintaining detections becomes far less painful than managing them purely through a UI.
Yes, there’s still upkeep. But compared to the manual overhead of UI-driven workflows, the long-term payoff is massive.
That’s why, even for a very small team, I’m convinced the investment is worth it.
Benefits
As Code (In General)
Once you get used to having your detections in an easily searchable codebase, you realize just how much friction the UI-only approach creates.
In the UI, you can’t simply search for detection logic. You can’t mass update rules from the same data source. You can’t easily reuse components. Every action feels one-off and manual.
With a centralized codebase, everything lives in one place - accessible through your IDE. That makes detection creation and maintenance dramatically easier.
And it’s not just about queries. With the right architecture, your DaC setup can also integrate things like runbooks, dashboard links, or quick links with embedded variables.
Bottom line - as your suite grows, a well-documented “as code” implementation actually scales better and becomes more maintainable than UI-based workflows.
Version Control & Code Reviews
Managing detections strictly through the UI leaves you with little traceability. If a faulty rule is pushed, good luck rolling it back - you won’t have access to change history or context.
With DaC, quality control shifts into familiar engineering territory: Git, versioning, and peer review.
Peer reviews before merges help catch logic errors and ensure changes are documented. Compare that to the UI, where it’s all too easy to click “enable” without proper testing.
And, unless you’ve got detections on your audit logs set up for your SIEM platform (thankfully we do, even though they don’t ship with them out-of-the-box) - no one may even know a new detection was added. Or worse: disabled.
Version control also helps keep the team dynamic. Often, junior and mid-level engineers will hesitate to make changes because they’re afraid of “breaking something.” With reviews, traceability, and rollbacks baked into the workflow, that fear largely disappears.
You’d have to try pretty hard to mess things up.
- Today’s Sponsor -

Whether it’s Detection Engineering, Incident Response, or Threat Huting - Security Operations is built on data. And as a Security Engineer, you need to make that data work for you. Selecty is a database-agnostic, sidecar query assistant built to do just that. Generate queries based on your table schehmas, optimize them to your use case, iterate on them quickly, and debug faster than ever - all in one sleek interface. Check it out!
CI/CD Linting and Testing
A proper CI/CD pipeline for detections is like having a built-in safety net. Every commit automatically tests your syntax and detection logic - removing guesswork and reducing human error.
Think about it: every time you push code, your detections validate themselves before they ever reach production. If configured properly, you can’t even deploy unless your tests pass.
This does two powerful things:
Creates a continuous feedback loop that minimizes the risk of broken detections slipping through.
Builds in positive friction Requiring test cases forces engineers to think more critically about their logic before submitting that PR.
In short, automation not only catches mistakes but also raises the overall bar for quality.
Detection Standardization
Standardization might sound nitpicky at first, but in practice it’s a game-changer for maintainability. By creating a consistent framework for detection development, you make the process predictable, scalable, and easier for others to contribute.
Instead of reinventing the wheel every time, engineers follow the same structure. Almost like filling out a form. This lowers the barrier to entry, accelerates onboarding, and ensures your detection library grows in a way that’s sustainable.
The result? Anyone on the team can contribute without friction, while the codebase stays clean and manageable long-term.
Side Note: As I’ve been porting over detections, this standardization also helps me fly through transferring them over. I literally feel like I’m filling out a form!
DataDog Implementation
When it came time to actually build, I set myself one rule: keep it simple, but don’t sacrifice scalability or maintainability.
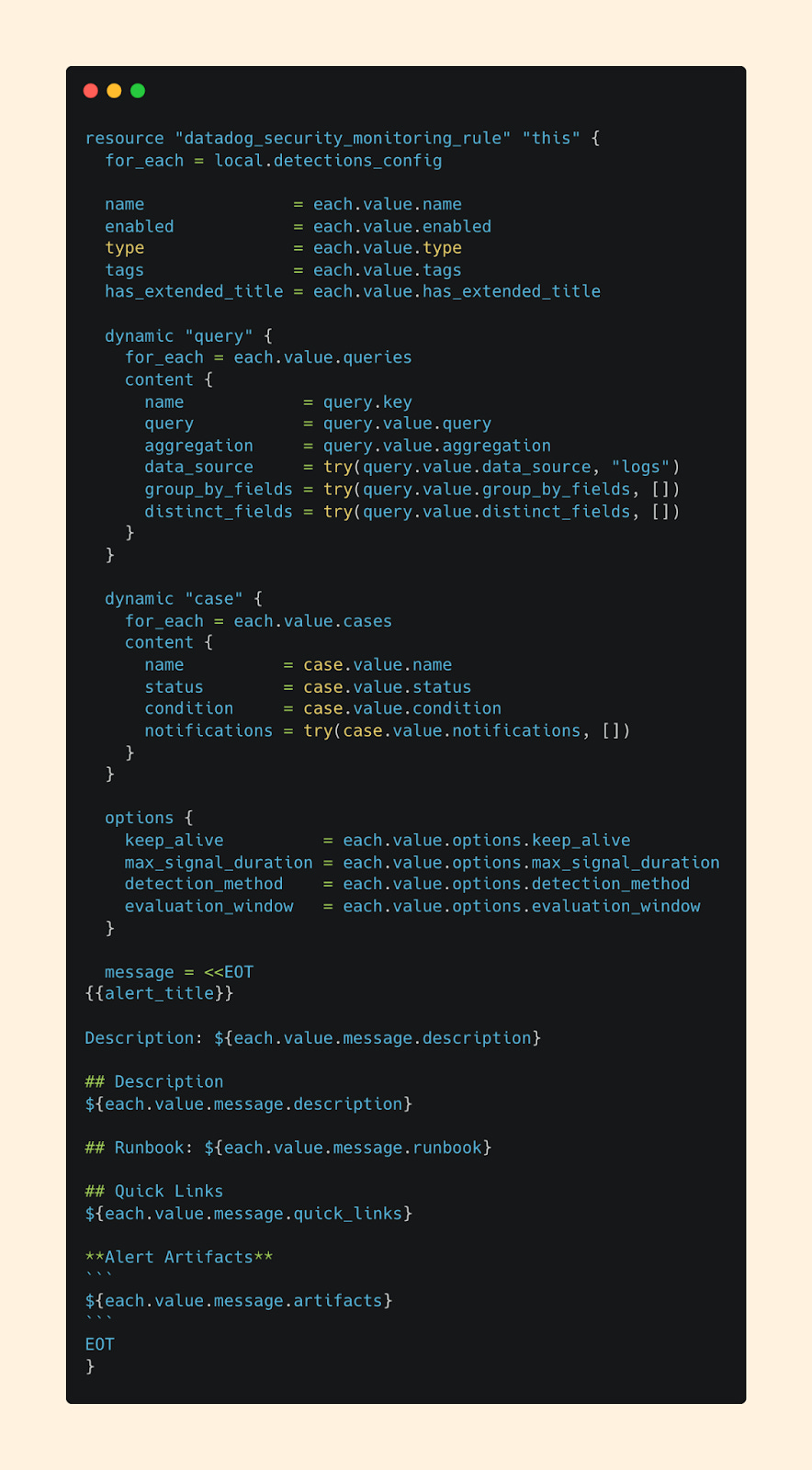
After digging through the DataDog Terraform docs, I landed on an approach that templatizes my terraform module while leaning on YAML files as the configuration file for detections.
Instead of writing Terraform for every detection, my team can now fill out a YAML file that looks and feels more like a form than raw code. The pipeline then takes care of the Terraform layer behind the scenes by looping through my detection folders.
While some may call this overengineering, I like to call it simplification.
By minimizing Terraform complexity and reusing a YAML template, we can port existing detections faster, create new detections with less friction, and empower everyone on the team (even those less comfortable writing code) to contribute meaningfully.
YAML gives us the right balance - structure enough to scale, simple enough for broad adoption.
📁 Scroll to the end to see the files. Or, want the raw files? Subscribers get them free through Cybersec OS!
Update 10/20/25 - Subscribers now get access to the MVP Repository in Cybersec OS. Kickstart your own DataDog DaC implementation now!
Deploy
On the deployment side, I added one extra layer to the typical Terraform flow.
Beyond the standard terraform plan and terraform apply, our CI/CD pipeline automatically runs tests against each detection using DataDog’s API.
Any folder with updated detection files triggers automated test runs, and all tests must pass before anything can be deployed.
My rule of thumb is that every detection must include at least three test cases: one true positive, one false positive, and one edge case. This is the number I landed on that forces the detection engineer to ensure their detection works as expected.
The pipeline enforces the true/false checks, while the edge case is a required part of peer review. This ensures detections aren’t just technically correct, but also thoughtfully designed.
Deployment becomes just as much about quality control as it does about pushing detections to production.

The Cybersec Café Discord is officially live! Join a growing community of cybersecurity professionals who are serious about leveling up. Connect, collaborate, and grow your skills with others on the same journey. From live events to real-world security discussions — this is where the next generation of defenders connects. Join for free below.
Why I View This as Our Ideal MVP Solution
Is this the most elaborate, rigorously tested detection-as code pipeline, battle hardened by our (non-existent) red team?
No.
What it is, though, is a minimal viable product that brings detections-as-code to a small team without the overhead of a massive pipeline, and still delivers most of the benefits of an as-code approach.
This solution lays the foundation for scalability and maintainability. It lowers the barrier to contribution, requiring only minimal Terraform knowledge, and keeps the team focused on what matters: shipping and refining detections.
It’s simple. It’s learnable. And it works.
And to me, seeing my team actually use this lightweight but powerful approach - that’s the real win.
Terraform File:
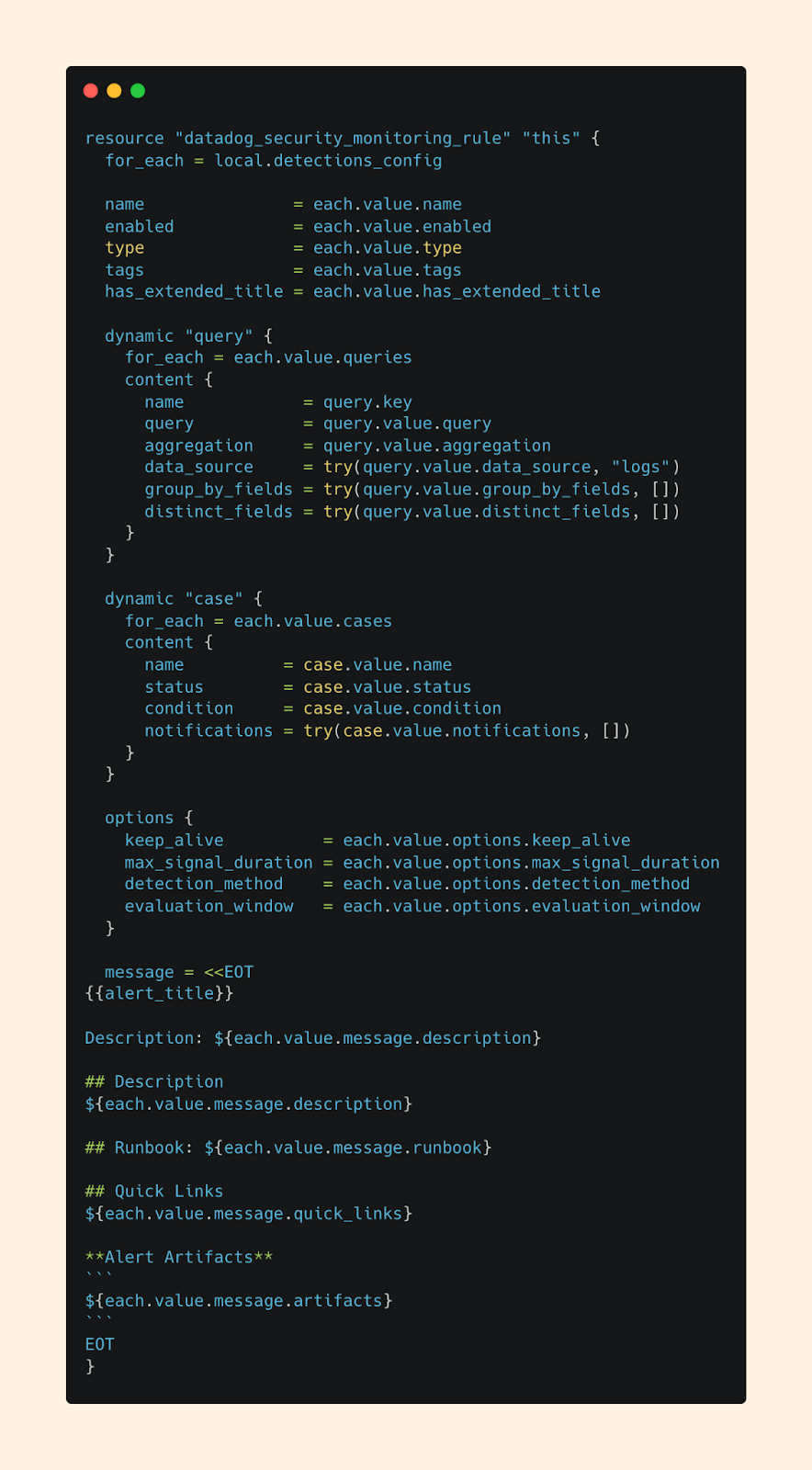
YAML File:
Securely Yours,
Ryan G. Cox
P.S. The Cybersec Cafe follows a weekly cadence.
Each week, I deliver a Deep Dive on a cybersecurity topic designed to sharpen your perspective, strengthen your technical edge, and support your growth as a professional - straight to your inbox.
. . .
For more insights and updates between issues, you can always find me on Twitter/X or my Website. Let’s keep learning, sharing, and leveling up together.
As an “ex-Datadog” this brought me much joy 💙